04 Proof of Work
Implementation Walkthrough
Screenshots from the live AWS environment showing each stage of the pipeline working end-to-end.
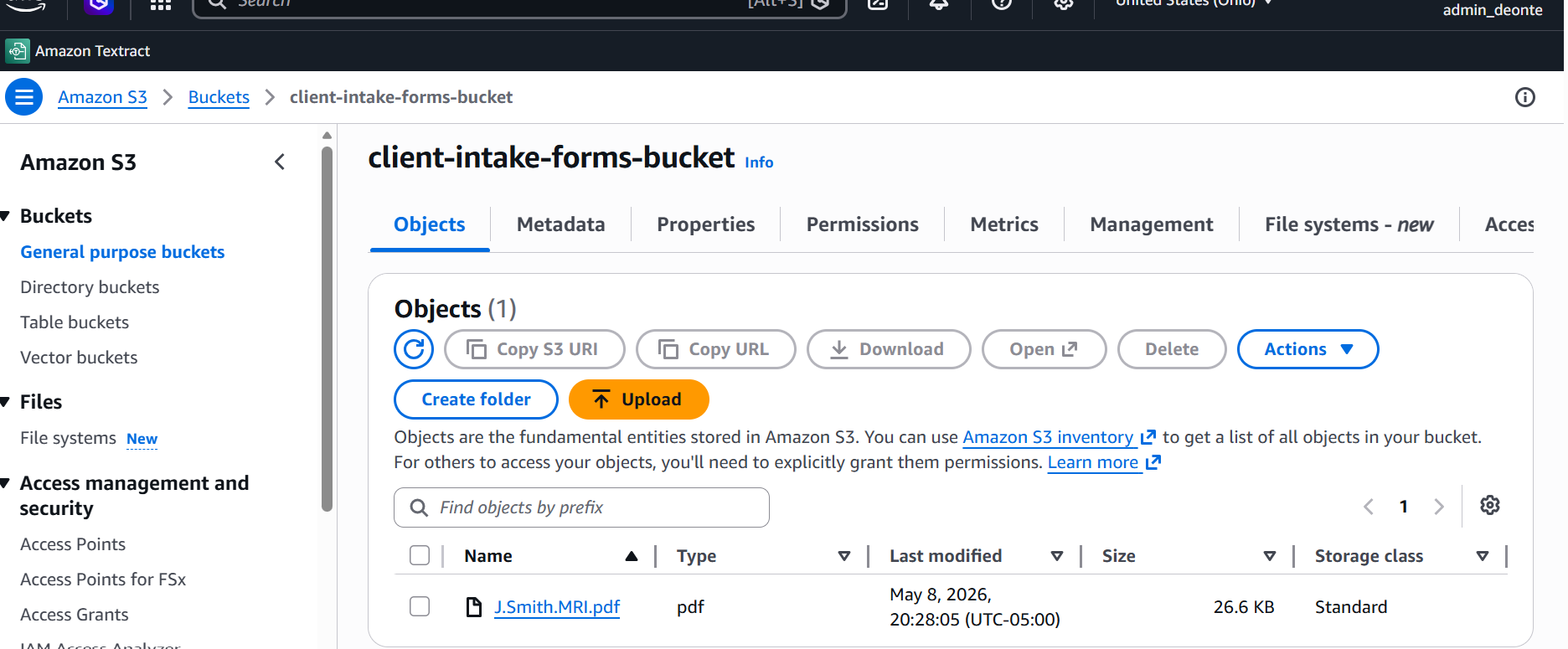
Amazon S3 · Entry Point
S3 Document Upload
Documents uploaded into S3 automatically trigger the serverless processing workflow.
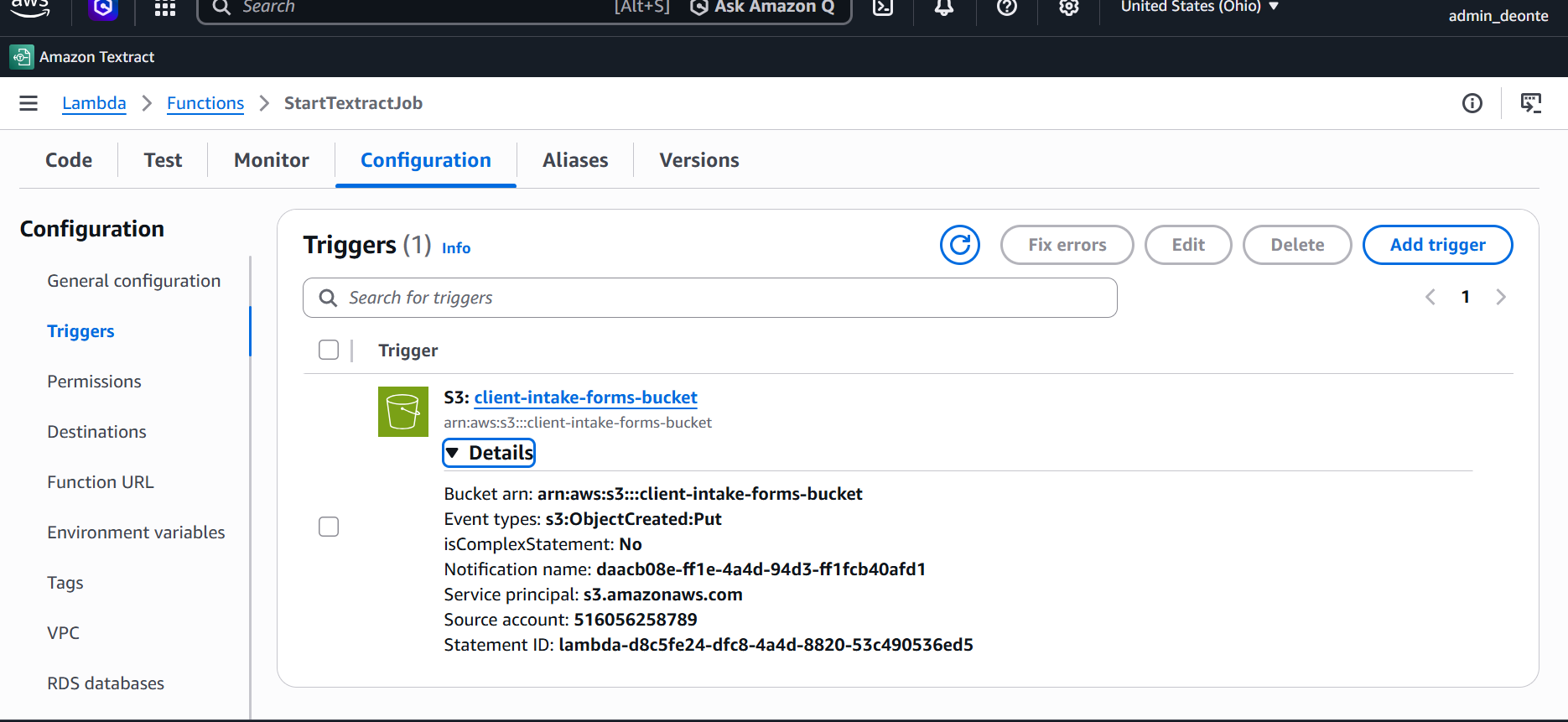
AWS Lambda · Trigger
Lambda Trigger Workflow
Lambda function connected to S3 events to start asynchronous Textract processing.
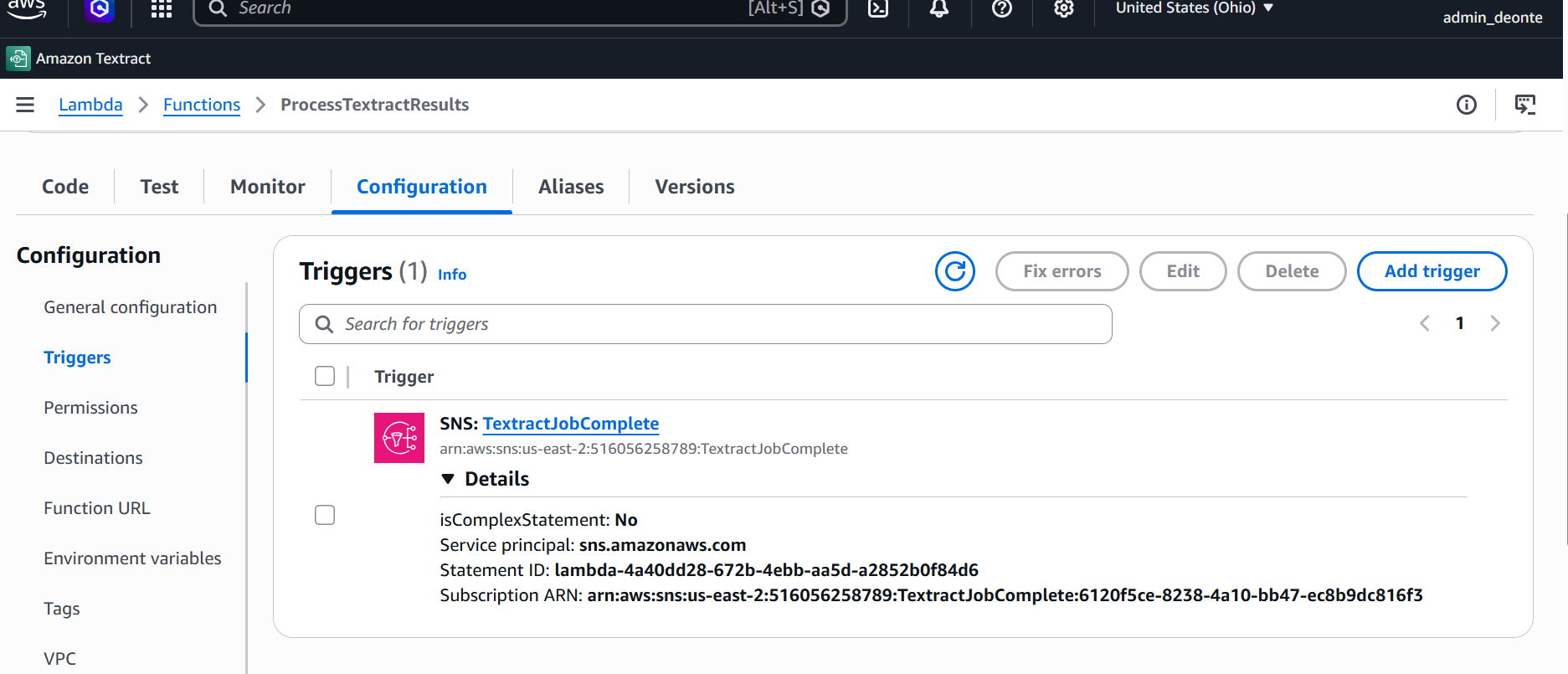
Amazon SNS · Async Notification
SNS Notification Trigger
SNS notifications trigger downstream processing once OCR extraction is complete.
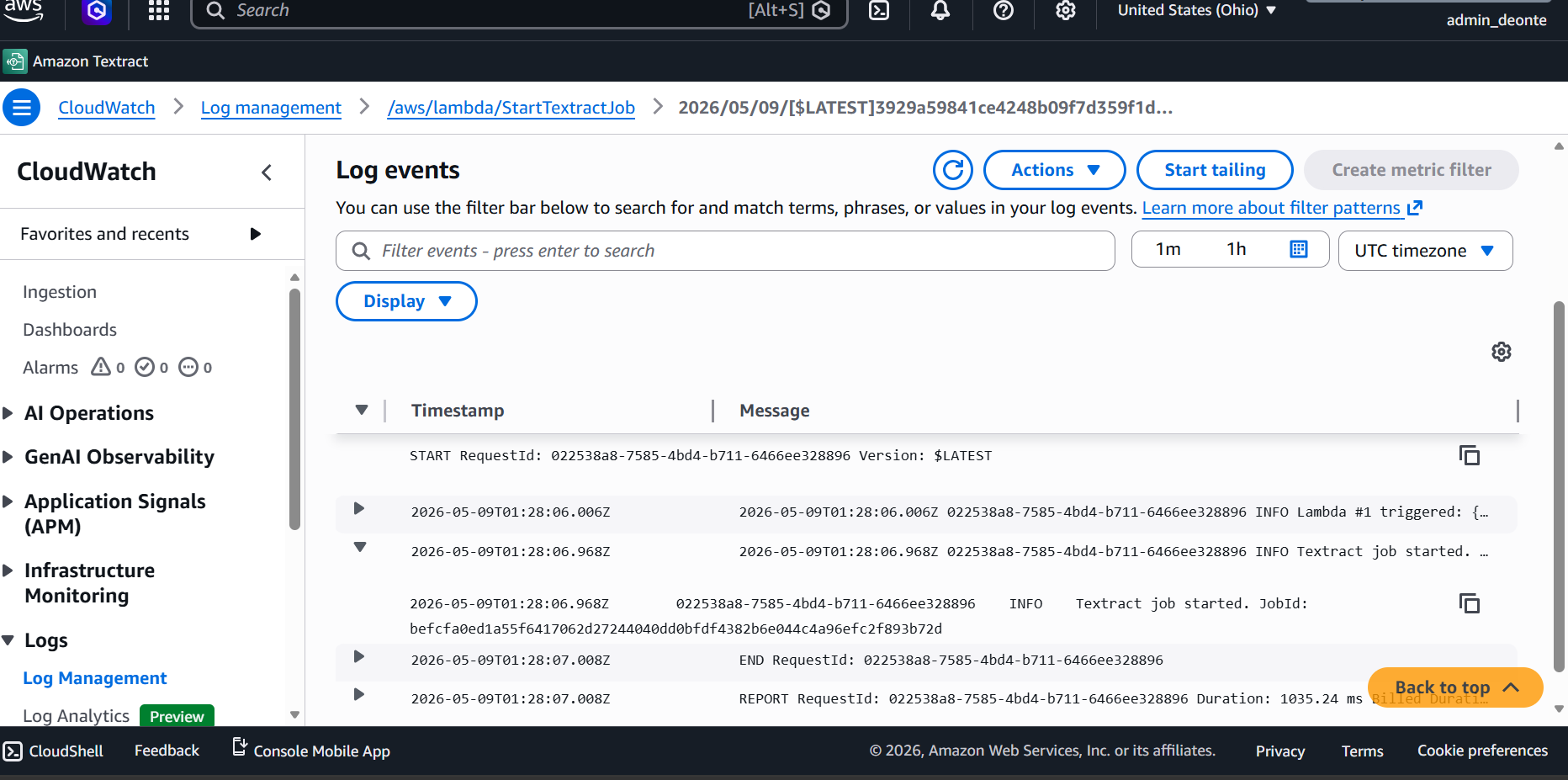
CloudWatch · Monitoring
CloudWatch Monitoring
CloudWatch logs showing successful Lambda execution and Textract job processing.
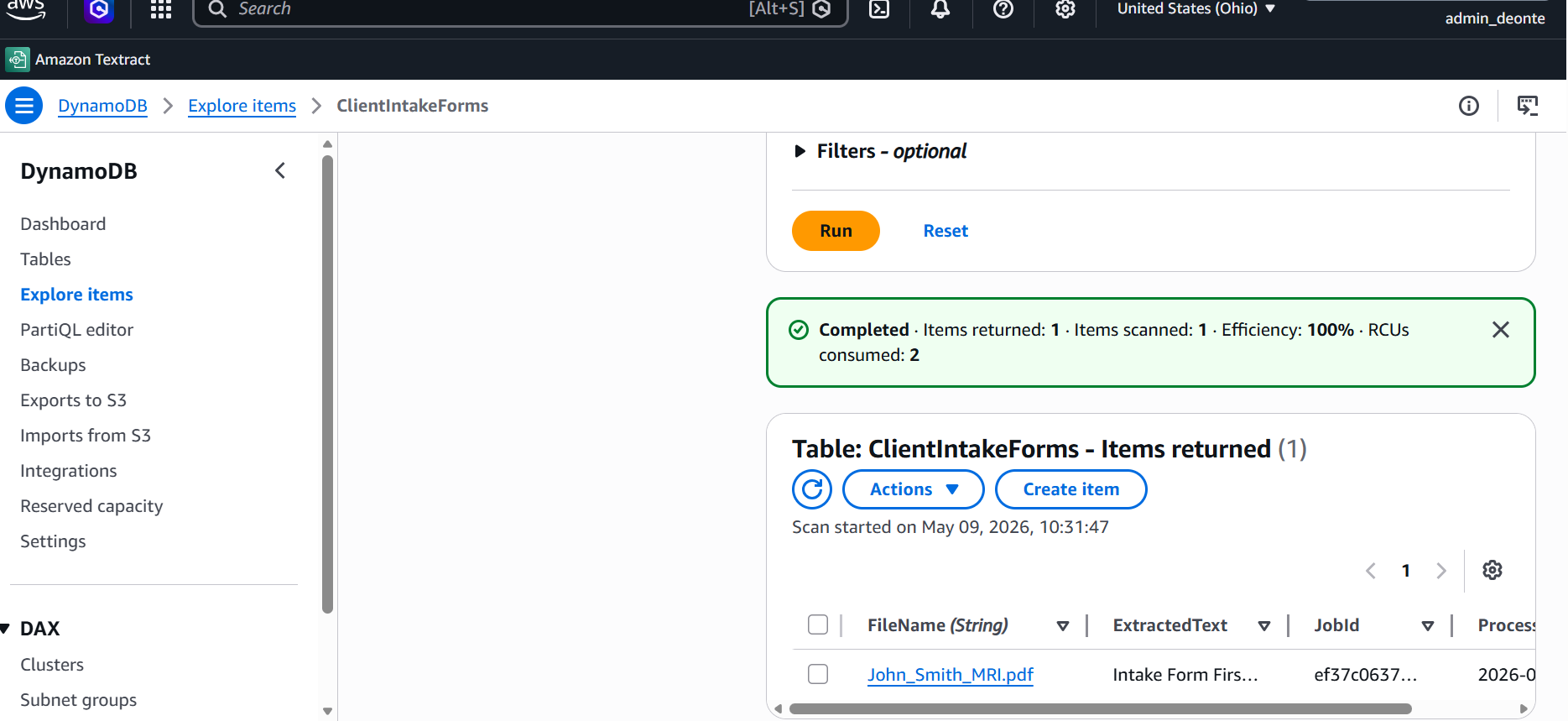
DynamoDB · Output
DynamoDB Processed Output
Processed intake data successfully stored in DynamoDB after OCR extraction and workflow completion.
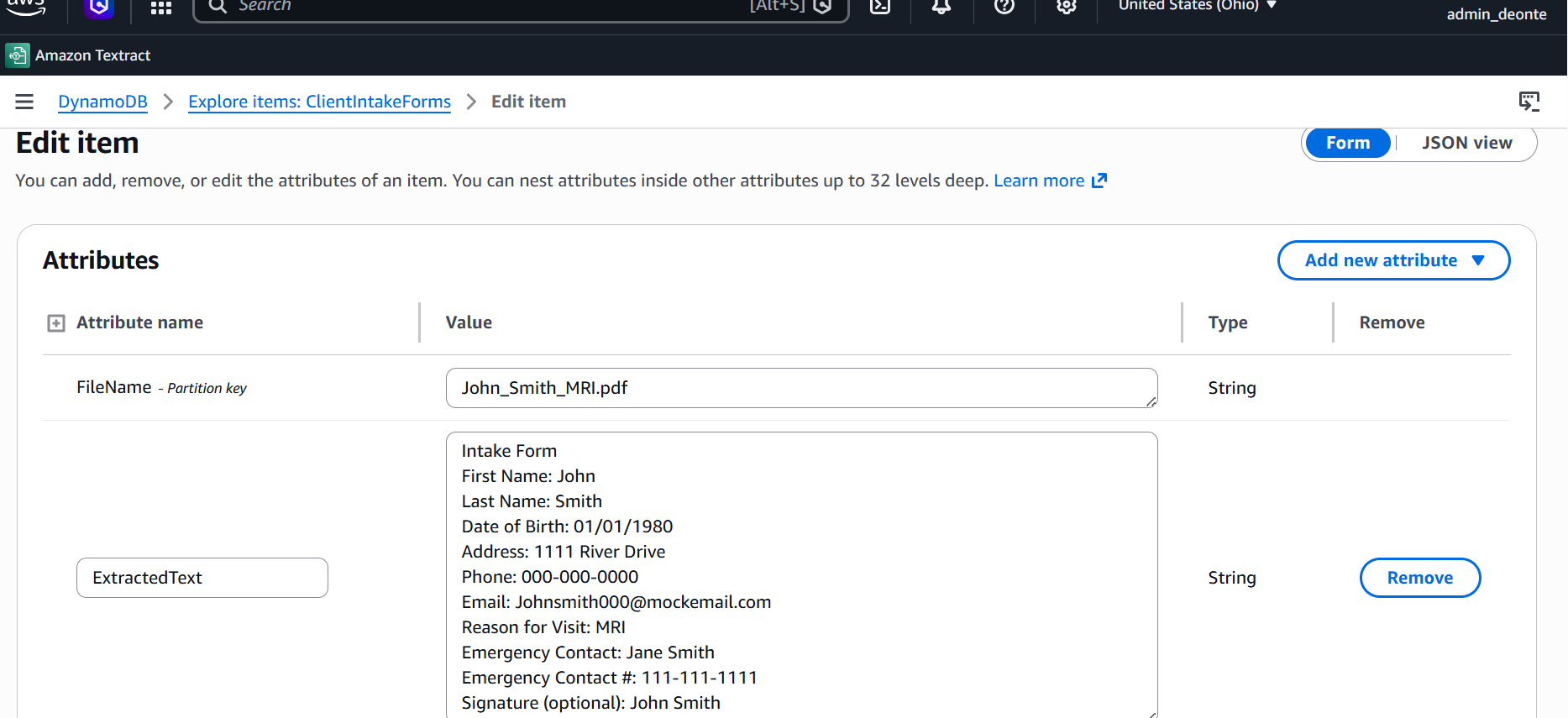
DynamoDB · Record Detail
Extracted Record Detail
The full extracted text from a client intake form, including name, DOB, address, and reason for visit, stored as structured data keyed by file name.